JavaScript im GEO: Was Onlineshops wirklich verlieren

Beispiel einer Antwort von ChatGPT
JavaScript ist im technischen SEO ein bekanntes Thema. SEOs stehen regelmäßig der Herausforderung gegenüber, dass Suchmaschinen wichtige Inhalte teilweise nicht korrekt auslesen, weil JavaScript verwendet wird. Durch die schnelle Entwicklung und Adaption von LLMs gilt das aber nicht mehr nur für klassische Suchmaschinen, sondern auch für einen völlig neuen Traffic-Kanal ‚GEO‘, welcher im modernen Onlinemarketing bei der Optimierung von Websites und Onlineshops zwingend berücksichtigt werden muss.
Ein Fachartikel von Dennis Heusener (8mylez GmbH)
-
Die Unterschiede zwischen Google- und LLM-Crawlern
- Praxisbeispiel 1: Der "Show More"-Button bei Kapten & Son
- Praxisbeispiel 2: Animiertes Zählerelement bei “Umzugskönig”
- Die Lösung: Inhalte maschinenlesbar machen
- Checkliste
- Fazit - Was das für Onlineshops konkret bedeutet
Chatbots wie ChatGPT oder Gemini werden zunehmend zur Produktrecherche genutzt. Während Google JavaScript zumindest grundsätzlich rendern kann, lesen LLM-Crawler nur das aus, was bereits beim ersten Laden der Seite im HTML steht. Was dort nicht vorhanden ist, existiert für diese Crawler schlicht nicht.
Um alltägliche Stolpersteine aufzuzeigen, habe ich zwei Praxisbeispiele mitgebracht, die verdeutlichen, wie schnell solche Fehler im Alltag passieren können. Als Beispiel dient hierfür ein Onlineshop mit einem "Show More"-Button und ein Trust-Element mit einem animierten Zählerelement.
Die Unterschiede zwischen Google- und LLM-Crawlern
Wenn Google eine Website crawlt, durchläuft der Prozess zwei Schritte. Erst wird das rohe HTML geladen, dann rendert der Crawler das JavaScript und analysiert die fertig gerenderte Seite. Das ist aufwändig und ressourcenintensiv, weshalb auch das JavaScript-Crawling nur eingeschränkt genutzt wird.
LLM-Crawler wie GPTBot von OpenAI oder ClaudeBot von Anthropic führen kein JavaScript aus. Sie lesen, was im HTML steht, während JavaScript nicht gerendert wird. Das bedeutet, dass Inhalte, die erst nach dem Rendern von JavaScript sichtbar werden, für diese Crawler völlig unsichtbar sind.
Jeder Onlineshop nutzt JavaScript, beispielsweise für Produktfilter, Tabs, Konfiguratoren und weitere dynamische Inhalte. Wer hier nicht aufpasst, verliert genau die Inhalte, die für Kaufentscheidungen relevant sind.
Praxisbeispiel 1: Der "Show More"-Button bei Kapten & Son
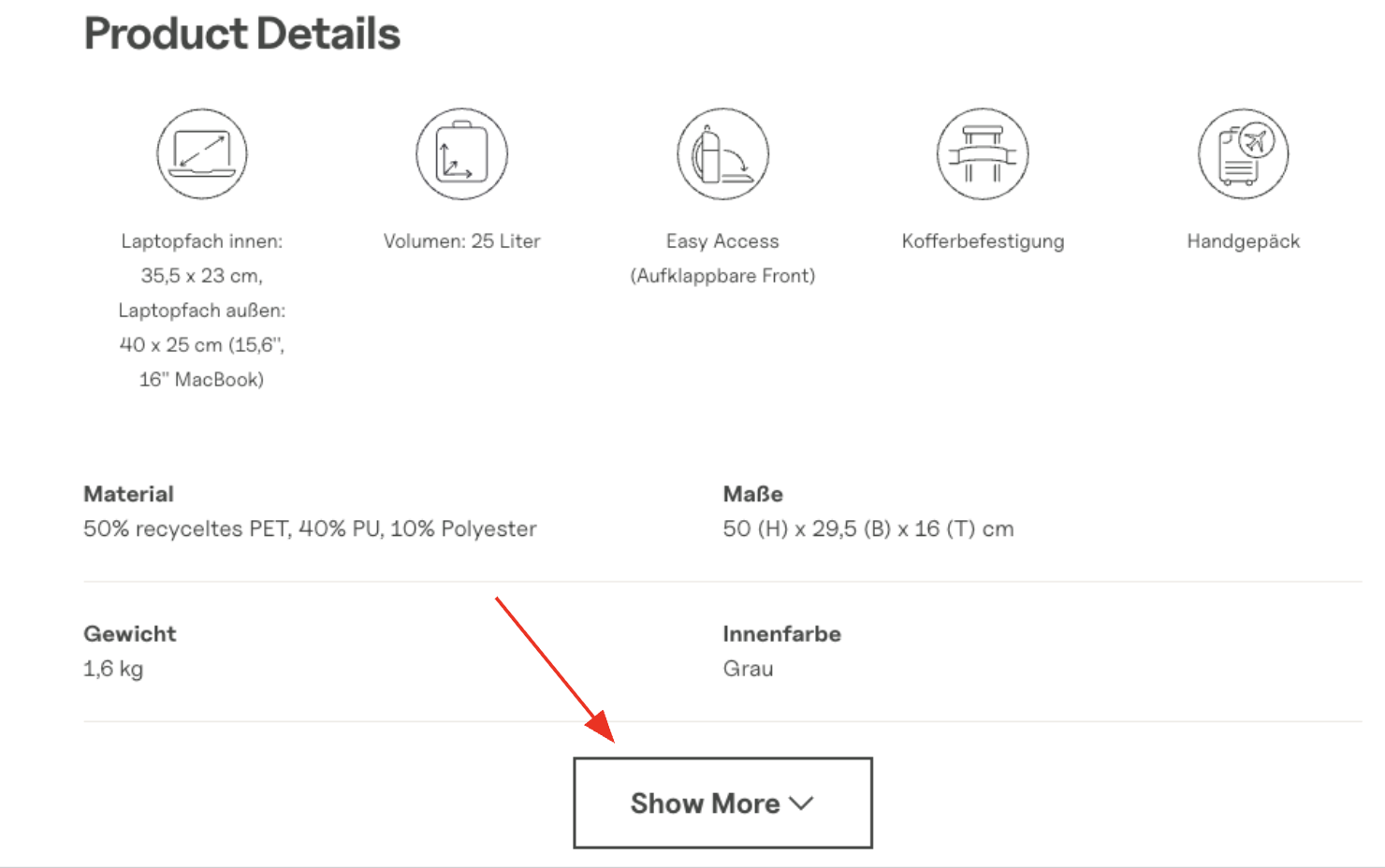
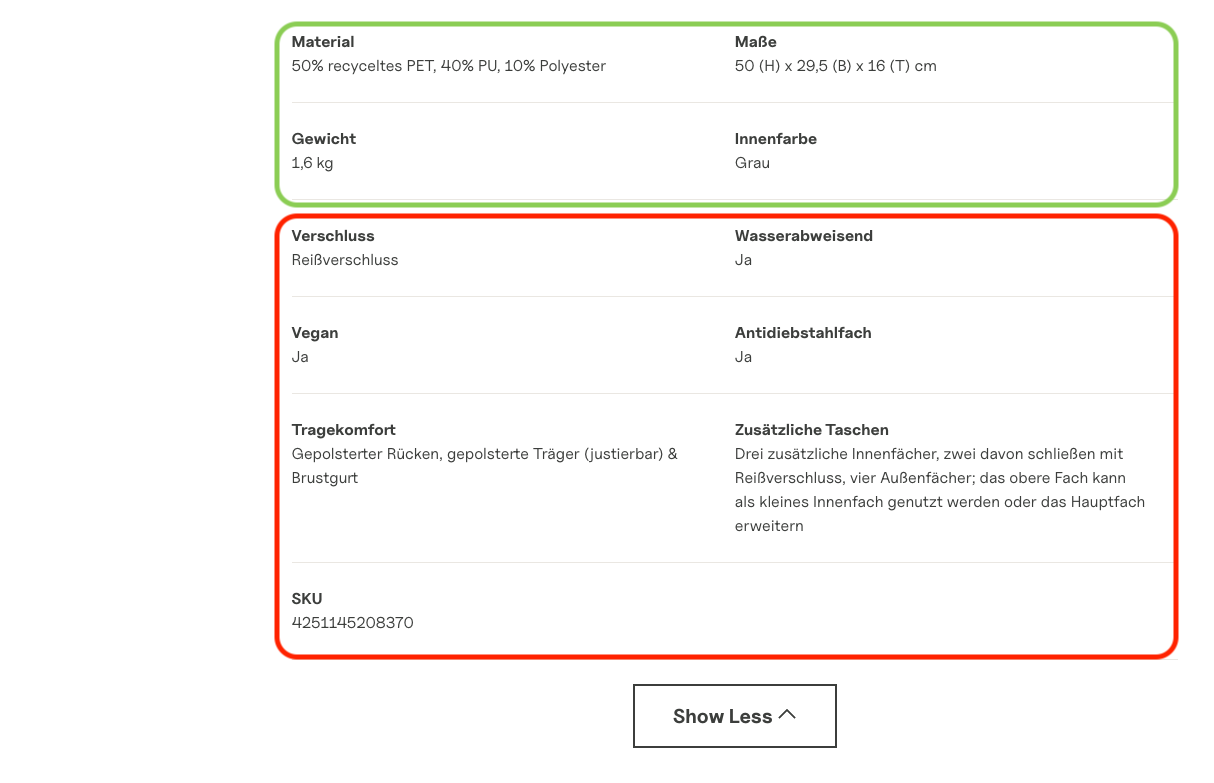
Kapten & Son ist ein bekannter Shop für Rucksäcke und Accessoires. Auf der Produktseite eines Rucksacks gibt es den Bereich "Product Details", in dem einige Eigenschaften direkt sichtbar sind: Material, Maße, Gewicht und Innenfarbe. Darunter folgt ein "Show More"-Button, der weitere Eigenschaften aufklappt.
Abgerufen: 26.01.2026
Abgerufen: 26.01.2026
Der Button sorgt dafür, dass der Inhalt deutlich aufgeräumt wirkt, doch das Problem liegt woanders.
Was im HTML steht und was nicht
Ein Blick in den Quelltext gibt Aufschluss, denn Material, Maße, Gewicht und Innenfarbe sind vorhanden, während die versteckten Eigenschaften dort nicht ersichtlich sind. Sie werden erst dann in das HTML geschrieben, wenn der Nutzer auf den Button klickt und JavaScript die Inhalte nachlädt.
Genau dieses Verhalten spiegelt sich auch im LLM-Crawler wider. Eigenschaften wie ein Antidiebstahl-Fach, die GTIN oder andere kaufentscheidende Merkmale sind für die KI schlicht nicht existent. Sucht ein Nutzer nach dem besten Rucksack mit einem Antidiebstahlfach, kann das entsprechende Produkt auf Basis der Informationen der Website nicht empfohlen werden.
Der Test: ChatGPT und Gemini
Ob ein LLM in der Lage ist, einen bestimmten Inhalt einer Website zu sehen, lässt sich einfach testen, indem man die URL in den Chatbot eingibt und direkt nach einem spezifischen Inhalt fragt. Für diesen Test wurde eine Produktseite eines Rucksacks im Onlineshop verwendet, mit der Frage: "Kannst du mir nur anhand dieser Landingpage die SKU des Produkts nennen?"

ChatGPT gab an, dass die Informationen auf der benannten Website nicht vorhanden seien. Die SKU stehe nicht im sichtbaren Produkttext und auch nicht in den Meta-Daten.
Gemini verhielt sich anders und nannte eine Nummer. Auf Nachfrage erklärte es, diese im Quellcode gefunden zu haben, konkret im JSON-LD-Bereich der Seite. Der Fund bedeutet nicht automatisch, dass Gemini in der Lage ist, strukturierte Daten korrekt interpretieren zu können, sondern hat eine Vermutung aufgestellt, dass es sich dabei um die GTIN handelt.
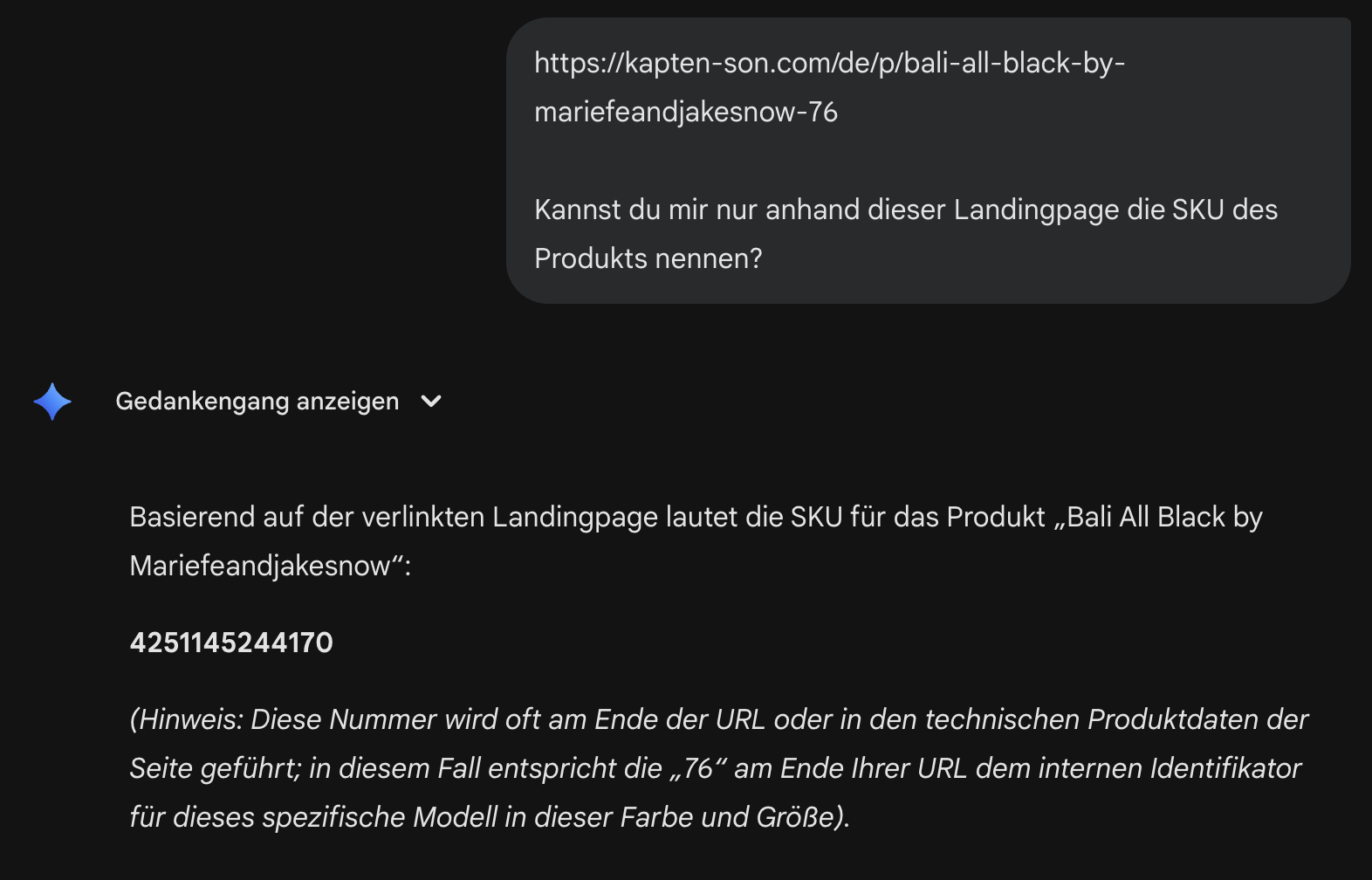
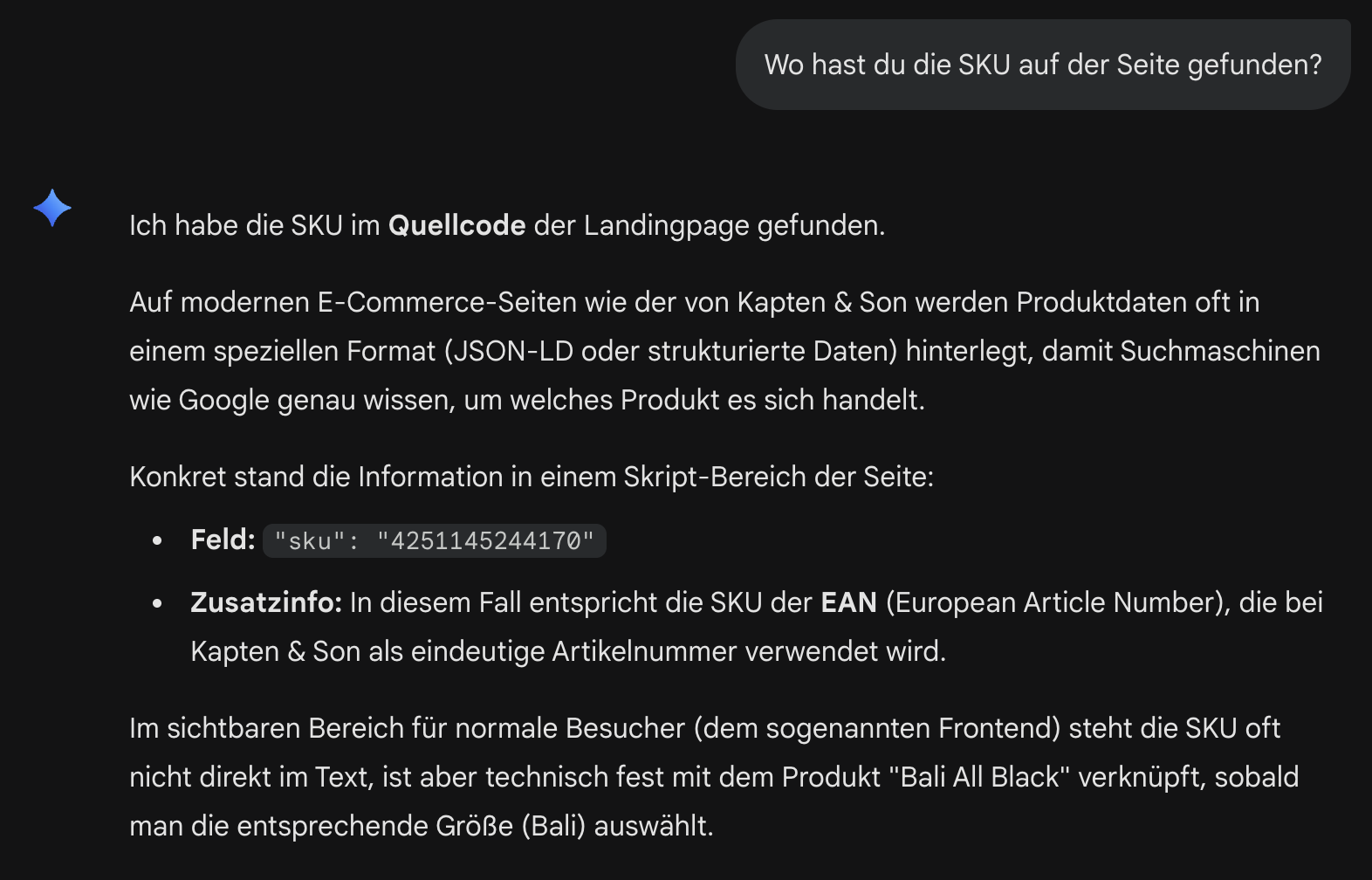
Beide Ergebnisse haben gemeinsam, dass sie nicht in der Lage waren, JavaScript zu rendern und die versteckten Produkteigenschaften aus der aufklappbaren Tabelle auszulesen. Gemini hat sich lediglich den strukturierten Daten im HTML bedient. Im SEO wird es bereits häufig empfohlen, aber auch für das Thema GEO ist das ein weiteres Argument dafür, die strukturierten Daten in seinem Onlineshop ordentlich zu pflegen.
Praxisbeispiel 2: Animiertes Zählerelement bei “Umzugskönig”
Ein weiteres, oft übersehenes Beispiel sind dynamische Trust-Elemente. Umzugskönig Heidelberg, ein Umzugsunternehmen aus Baden-Württemberg, zeigt auf seiner Homepage prominent drei Kennzahlen: über 20 Jahre Erfahrung, 5.000 zufriedene Kunden und 350.000 gefahrene Kilometer. Für Besucher wirkt das überzeugend, solche Elemente sollen gezielt Vertrauen aufbauen.

Die konkreten Zahlen existieren im HTML allerdings nicht. Dort stehen nur Platzhalter, die tatsächlichen Werte werden beim Laden der Website per JavaScript berechnet und eingesetzt. Wer ChatGPT direkt nach den Erfahrungsjahren oder der Kundenzahl fragt und dabei die URL der Seite angibt, bekommt keine Antwort auf Basis dieser Zahlen — sondern den Hinweis, dass die Felder nur Platzhalter wie „0+" und „0 K" enthalten und keine konkreten Werte vorhanden seien.
Ähnliche Risiken können bei Live-Zählern entstehen wie „X Personen schauen sich dieses Produkt gerade an", bei Bewertungswidgets, die per JavaScript geladen werden, oder bei Inhalten, die abhängig vom Nutzerverhalten erscheinen. Alles, was erst nach dem JavaScript-Rendering sichtbar wird, bleibt für LLMs unsichtbar.
Die Lösung: Inhalte maschinenlesbar machen
Das Grundprinzip ist einfach. Was ein LLM lesen soll, muss bereits beim ersten Laden der Seite im HTML vorhanden sein. Ob ein Button den Inhalt visuell versteckt oder aufklappt, ist dabei zweitrangig. Entscheidend ist, ob der Inhalt im Quelltext steht, bevor JavaScript ausgeführt wird.
Wie Autodoc es besser macht
Autodoc, ein großer Online-Händler für Kfz-Ersatzteile, nutzt auf seinen Produktseiten ebenfalls eine aufklappbare Tabelle mit Kompatibilitätsdaten. Auch dort gibt es einen "Mehr"-Button, der weitere Zeilen einblendet, darunter die Hersteller-Artikelnummer und OE-Referenznummern.
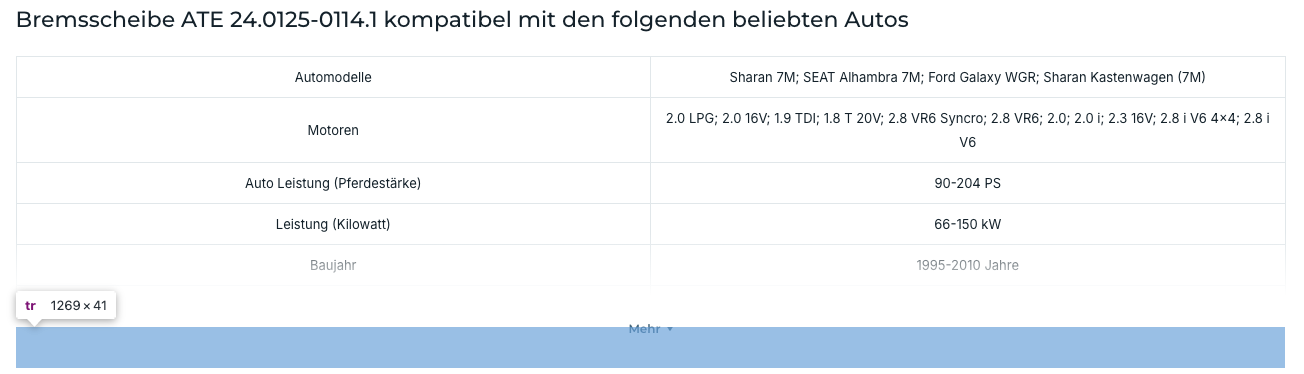
Abgerufen: 16.02.2026
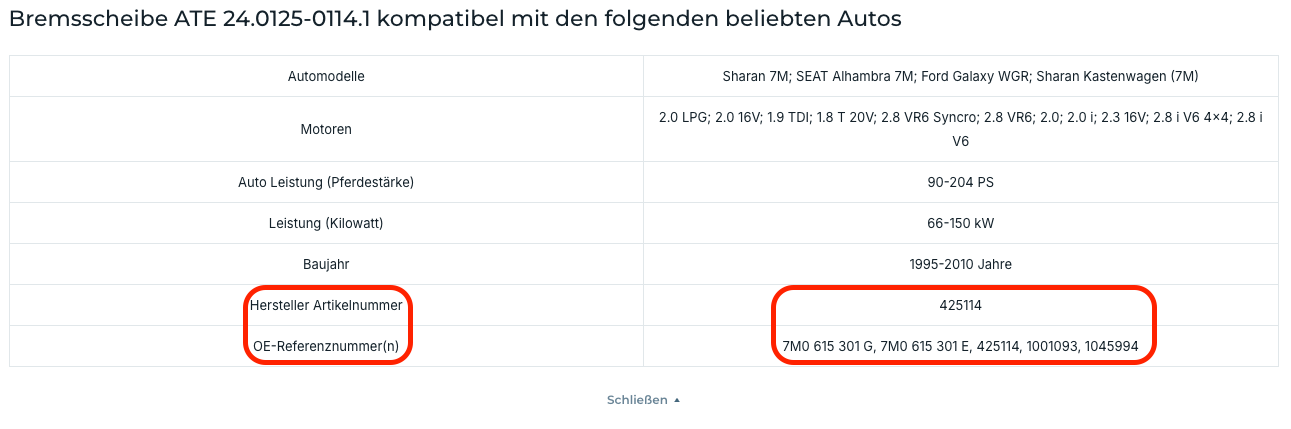
Abgerufen: 16.02.2026
Der Quelltext offenbart hingegen, weshalb die Umsetzung LLM-freundlich ist: Die Daten sind bereits im HTML vorhanden, der Button blendet sie nur visuell aus. Technisch gesehen sind sie von Anfang an da und ein LLM-Crawler liest sie problemlos, unabhängig davon, ob ein Nutzer auf "Mehr" klickt oder nicht.

Abgerufen: 16.02.2026
Konkrete Empfehlungen
Wichtige Inhalte nicht per JavaScript ausspielen:Produkteigenschaften, Trust-Signale und andere kaufentscheidende Inhalte sollten von Anfang an im HTML stehen. JavaScript darf die Darstellung steuern, aber nicht der einzige Weg sein, über den Inhalte in die Seite gelangen.
Serverseitiges Rendering als Alternative:Falls sich JavaScript nicht vermeiden lässt, kann serverseitiges Rendering (SSR) helfen. Dabei wird der Inhalt bereits auf dem Server verarbeitet und als fertiges HTML ausgeliefert. Das funktioniert vor allem dann, wenn Inhalte bislang clientseitig nachgeladen werden, zum Beispiel über API-Abfragen im Browser.
Trust-Elemente statisch hinterlegen:Zahlen wie "15 Jahre Erfahrung" oder "über 10.000 zufriedene Kunden" gehören als echter Text ins HTML, nicht als JavaScript-berechneter Wert in einen Platzhalter. Falls die Elemente aus gestalterischen Gründen ausgeblendet werden sollen, ist das in Ordnung, solange die Werte im HTML vorhanden sind und von Crawlern gelesen werden können.
Strukturierte Daten ergänzen:Schema.org-Markup im JSON-LD-Format hilft LLMs, Produktdaten eindeutig zu verstehen und zuzuordnen. Der Test hat gezeigt, dass Gemini diese Daten erkennt. Für Shops, die Schema.org bereits einsetzen, ist das ein echter Vorteil.
Bewertungen im Blick behalten:Viele Shops binden Bewertungen über externe Skripte ein, zum Beispiel über Widgets von Trusted Shops oder Google. Werden diese Bewertungen erst per JavaScript geladen, sind sie für LLM-Crawler unsichtbar. Bewertungen gehören zu den stärksten Vertrauenssignalen und sollten daher auch im HTML zugänglich sein.
Inhalte sichtbar statt nur zugänglich machen:Im SEO ist es seit Jahren ein Diskussionspunkt, ob versteckter Content genauso gewichtet wird wie sichtbarer Content. Bei LLMs ist die Antwort eindeutiger. Wichtige Produktinformationen sollten vollständig sichtbar sein, ohne dass ein Klick nötig ist. Das ist die sicherste Option.
Analyse per Screaming Frog:Die Website kann vollständig gecrawlt werden und das statische HTML sowie das gerenderte HTML und dessen Unterschiede werden angezeigt. Außerdem gibt es eine Spalte für "JS-Wörter", die offenbart, wie viel Prozent der Wörter per JavaScript eingeladen werden, sodass die URLs mit dem höchsten Anteil direkt ersichtlich werden. Wie die obigen Beispiele zeigen, können aber bereits wenige Wörter einen entscheidenden Unterschied machen. Daher lohnt sich auch bei niedriger JS-Wortzahl ein genauerer Blick.
Seite ohne JavaScript laden:Im Browser lässt sich JavaScript deaktivieren. Es ist empfehlenswert, dies zu tun und die eigene Website anschließend zu überprüfen. Ein Blick auf andere Onlineshops hilft zusätzlich, ein Gefühl dafür zu bekommen, wie Websites ohne JavaScript aussehen und welche Inhalte dabei verloren gehen.
So testen Sie selbst
Der einfachste Weg führt direkt über den Browser. Produktseite öffnen, Rechtsklick, Seitenquelltext anzeigen. Dann per Strg+F nach dem Inhalt suchen, den man prüfen möchte. Taucht er dort nicht auf, sieht ein LLM-Crawler ihn höchstwahrscheinlich auch nicht. Alternativ lässt sich die URL direkt in ChatGPT oder Gemini eingeben und nach einem spezifischen Inhalt fragen. Die Antwort zeigt schnell, was der Crawler tatsächlich lesen konnte und was nicht.
Kurze Checkliste für den Anfang
- Sind alle kaufentscheidenden Produkteigenschaften bereits im HTML vorhanden?
- Werden Trust-Elemente wie Erfahrungsjahre und Kundenzahlen als echter Text hinterlegt oder per JavaScript berechnet?
- Werden Bewertungen über externe Skripte eingebunden und sind sie für Crawler zugänglich?
- Sind Schema.org-Markup und strukturierte Daten für wichtige Produkte vorhanden?
- Wurde der Quelltext relevanter Produktseiten auf fehlende Inhalte geprüft?
- Wurde eine Screaming Frog-Analyse auf JavaScript-Wortzahl durchgeführt?
- Wurde ein direkter Test mit einem LLM durchgeführt?
Fazit - Was das für Onlineshops konkret bedeutet
Auch wenn viele Auswertungen von GA4-Konten aufzeigen, dass der Referrer-Traffic von LLMs vergleichsweise gering ist, übernehmen Chatbots zunehmend wichtige Touchpoints in der User Journey und sind damit sehr relevant. Ob ein bestimmtes Produkt dabei auftaucht, hängt davon ab, ob das LLM die relevanten Eigenschaften überhaupt lesen konnte. Es geht dabei nicht darum, den gesamten Shop sofort umzubauen. Sinnvoller ist es, Prioritäten zu setzen. Welche Inhalte sind kaufentscheidend? Produkteigenschaften, technische Spezifikationen, Kompatibilitätsangaben und Trust-Elemente sind die Bereiche, die zuerst geprüft werden sollten.
Über Dennis Heusener
 Dennis Heusener ist Growth Marketing Manager bei der 8mylez GmbH, einer Full-Service-Shopware-Agentur aus Paderborn, die sich auf die Entwicklung, Betreuung und Optimierung von E-Commerce-Shops spezialisiert hat. In seiner Rolle als Growth Marketing Manager ist er verantwortlich für die strategische Weiterentwicklung und operative Umsetzung von Marketing- und Wachstumsmaßnahmen im digitalen Umfeld. Er fokussiert sich dabei auf die Steigerung von Sichtbarkeit und Performance im E-Commerce-Bereich sowie auf datengetriebene Optimierung von Marketingkanälen und Kampagnen.
Dennis Heusener ist Growth Marketing Manager bei der 8mylez GmbH, einer Full-Service-Shopware-Agentur aus Paderborn, die sich auf die Entwicklung, Betreuung und Optimierung von E-Commerce-Shops spezialisiert hat. In seiner Rolle als Growth Marketing Manager ist er verantwortlich für die strategische Weiterentwicklung und operative Umsetzung von Marketing- und Wachstumsmaßnahmen im digitalen Umfeld. Er fokussiert sich dabei auf die Steigerung von Sichtbarkeit und Performance im E-Commerce-Bereich sowie auf datengetriebene Optimierung von Marketingkanälen und Kampagnen.